
As from the above image it's clear that the Rendergraph has evolved to contain buffers, image layout transitions, berries, chipmunks and what not. The first part is available here: Conundrum Of Multipass Rendering. The final result is consistent rendering loops with image layout transitions and synchronizations working without triggering any Vulkan validation errors. The last post had addressed the creation and management of tasks, this one will address the management of task submission to gpu.
Command Buffer Assignments

The above image shows the task flow and the required submission order which was getting stored in a linear array. The color coding matches the one used in the Rendergraph image. The renderer has been setup to use dedicated queues for each type of tasks namely graphics, compute, transfer and presentation.
The first job was to assign command buffers to tasks. Sticking only to primary command buffers. The simple strategy was while iterating through the linear array of tasks, note down the queue switches. It’s at the switch and at the start that we assign new command buffers to the tasks. In our case, task1_T0_E0 gets a new command buffer and the same command buffer trickles down to task1_T2_E2. At the switch to compute, task3_T1_E1 gets a new command buffer. Similarly, all the other tasks get a command buffer. The tasks are provided with the optional info to start and stop the command buffer recording, even this info gets generated at the queue switch. At the queue switch, the previous task was asked to stop recording and the current task was asked to start the recording (of its new command buffer). The below image shows the command buffer details. The green and red dots specify start and stop of command buffer recording respectively.

Inter Queue Synchronizations
As we are dealing with multiple queues, we need the task submissions to be synchronized. Vulkan without synchronizations, is like a library without Kafka. Semaphores make an entrance. Fences could also have entered but at this moment downloading tasks are not implemented, although they are used to complete the render loop, as shown later.
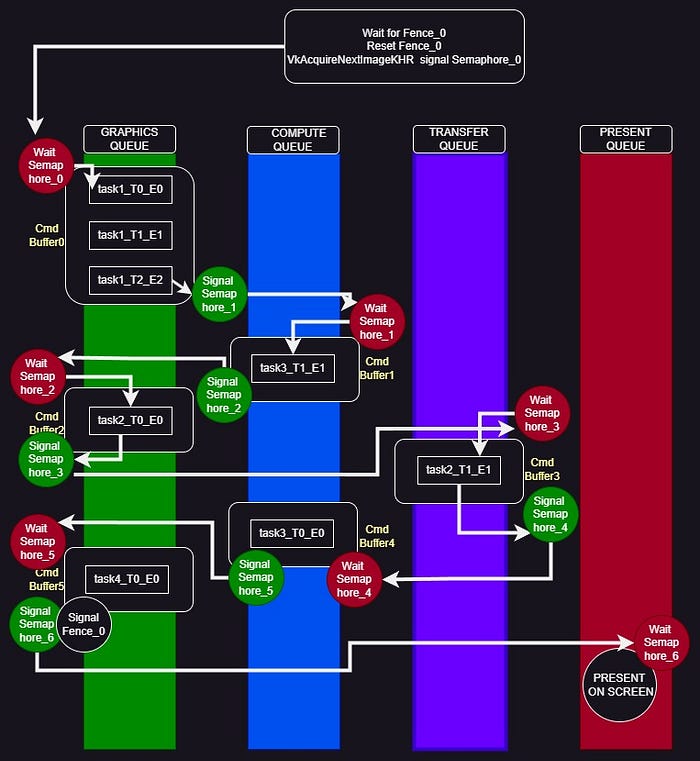
The above image shows the synchronization entities required for a single render loop. Let’s deal with semaphore assignments first.
The semaphores are also assigned at the queue switch or start. The last task within a set of tasks in the same queue will contain a submission info. The info will consist of wait, signal semaphore and an optional fence. The first submission will have a signal semaphore and optional wait semaphore/fence. This signal semaphore gets passed to the next submission info as the wait semaphore along with a new signal semaphore. The cycle repeats till we reach the last task. Hence, we have task submissions which are executed in gpu in a pre-defined order.
Let’s dig into the render loop. The fences are created in signaled form. Hence, at the start, the wait for the fence just passes and post which the fence gets reset. The same fence is used in the last submission, which will be waited after completion of a set of frame in flights (multiple frames are calculated without waiting for render completion).VkAcquireNextImageKHR is a given a semaphore to signal, which acts as the wait semaphore for the first command buffer/s submission. The last submission’s signal semaphore is passed onto the VkPresentInfoKHR as the wait semaphore. Hence, it waits for the last task completion before presenting it on the screen.
Intra Queue Synchronizations
As the spec says, there is no guarantee about the completion order of the tasks we need to handle the cache flushes and invalidations using barriers or events. In our case, its barriers.
The tasks contain a list of inputs (resources): images or buffers. We need to track down the lifetime of these resources. In case of images, it allows us to get the load and store values for an image in a barrier. A much more advanced strategy would have allowed us memory aliasing using the life time of the resources but not happening in our case. While iterating through the task array, we map each resource to the tasks and expected layouts (in case of images), as shown below.
struct TaskImageInfo
{
Renderer::RenderGraph::Task* m_task;
Renderer::RenderGraph::Utils::ResourceMemoryUsage m_usage;
Core::Enums::ImageLayout m_previous, m_expected;
};
std::map<Resource*, std::vector<TaskImageInfo>> resourceInfo;Based on previous and expected layouts we will calculate src, dst stages and access masks. This will allow us to create (image) barriers. In case of buffers, we are storing the previous and current usage mechanism (shader type or transfer src/dst) in order to calculate the above. And yes, the VkPhysicalDeviceSynchronization2Features have been enabled to use vkCmdPipelineBarrier2. Please note, if different queue families are involved additionally the queue ownership transfer will be required.
typedef struct VkImageMemoryBarrier2 {
VkStructureType sType;
const void* pNext;
VkPipelineStageFlags2 srcStageMask;
VkAccessFlags2 srcAccessMask;
VkPipelineStageFlags2 dstStageMask;
VkAccessFlags2 dstAccessMask;
VkImageLayout oldLayout;
VkImageLayout newLayout;
uint32_t srcQueueFamilyIndex;
uint32_t dstQueueFamilyIndex;
VkImage image;
VkImageSubresourceRange subresourceRange;
} VkImageMemoryBarrier2;The abovementioned map gives us a way to calculate the load and store op. in case of images. The first task containing the image, will have a Load as loadOp if it’s previous layout is not in VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL or VK_IMAGE_LAYOUT_UNDEFINED. The storeOp gets Store throughout till the last task where it gets DontCare. Further optimizations can be made with better strategy to decide store and load ops. The load and store ops are needed for VkRenderingAttachmentInfo to be used for dynamic rendering, the conventional Vulkan render pass and framebuffer have been replaced. A much more detailed explanation of Vulkan dynamic rendering can be found here: Vulkan dynamic rendering.
typedef struct VkRenderingAttachmentInfo {
VkStructureType sType;
const void* pNext;
VkImageView imageView;
VkImageLayout imageLayout;
VkResolveModeFlagBits resolveMode;
VkImageView resolveImageView;
VkImageLayout resolveImageLayout;
VkAttachmentLoadOp loadOp;
VkAttachmentStoreOp storeOp;
VkClearValue clearValue;
} VkRenderingAttachmentInfo;The intra queue synchronizations could have been explained in a dedicated blog but for now this looks sufficient.
It does add something to my peace, when such a big ass setup works. Next step: do some actual rendering.
